如何导出 ChatGPT Team 账户的记忆:离职时你会失去什么
超过 700 万职场用户在工作中使用 ChatGPT Team。当你离职时,那份 AI 记忆会留在原地。这里揭示真正的风险——以及如何保护你的上下文。
ChatGPT Team 于 2024 年 1 月推出。到 2025 年 11 月,OpenAI 报告付费职场席位已超过 700 万——不到两年增长了 47 倍。今天,92% 的 Fortune 500 公司在使用 ChatGPT,28% 的在职成年人在工作中使用它,其中大多数人每周使用四天或更多。
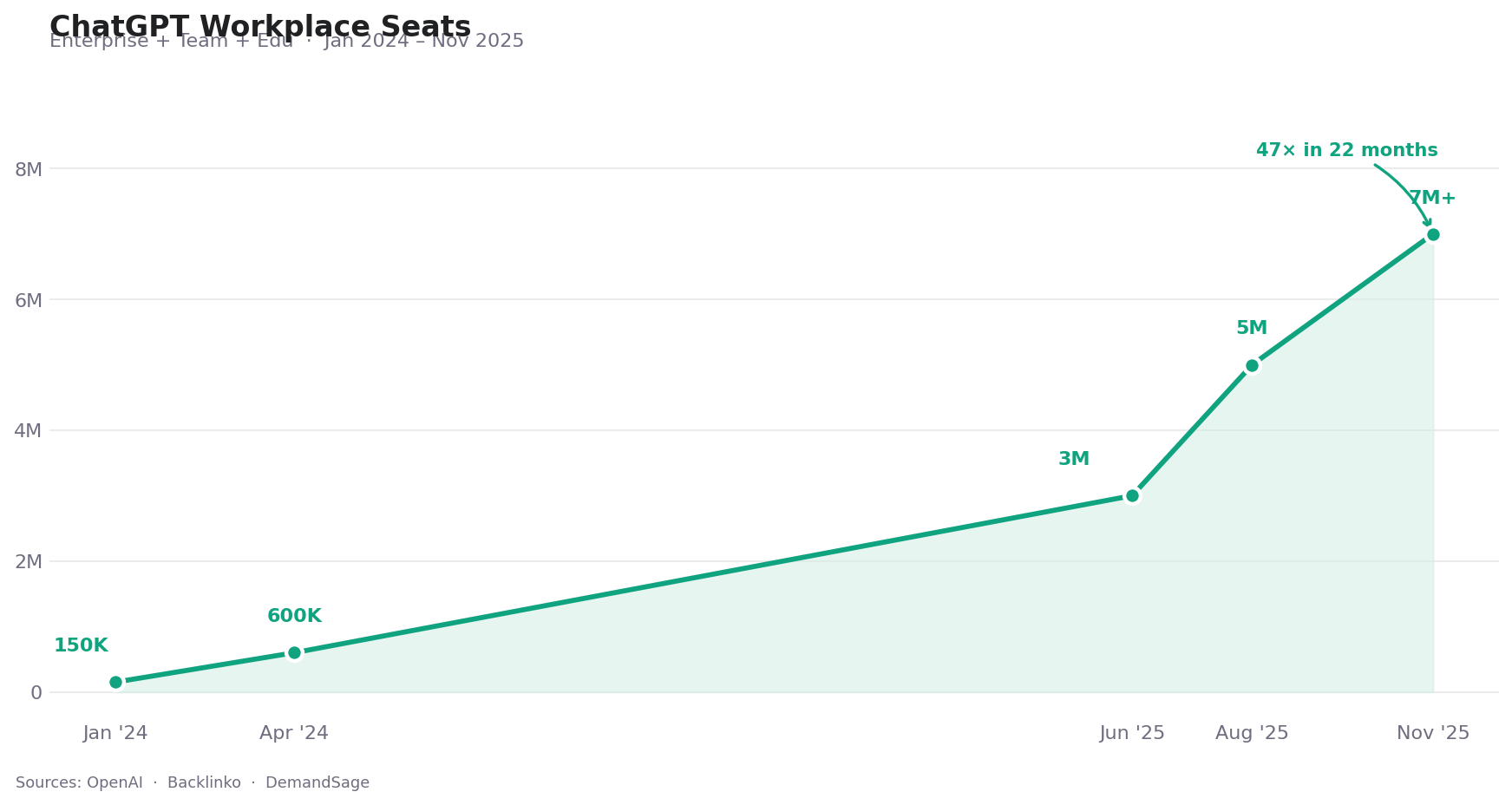 ChatGPT 企业与团队席位增长情况,2024 年 1 月至 2025 年 11 月。数据来源:OpenAI、Backlinko、DemandSage
ChatGPT 企业与团队席位增长情况,2024 年 1 月至 2025 年 11 月。数据来源:OpenAI、Backlinko、DemandSage
在这些数字背后,有一些不那么显眼的东西:这 700 万用户中的每一位都在构建某种东西。不仅是使用历史——而是一个越来越懂他们如何思考、如何写作、在乎什么的 AI。OpenAI 自己的研究发现,经常使用 AI 的人每天节省 40 到 60 分钟。这些收益的大部分并非来自模型本身的能力——而是 AI 了解你。
有一件事没有写进员工手册:那份上下文属于公司账户,不属于你。
当你换工作时,它会留在原地。
一种新型的职业资产——但你并不拥有
传统的离职交接有清晰的逻辑:你的判断和经验属于你;公司的文件、知识产权和数据属于公司。这个边界几十年来都运转良好。
AI 创造了一个第三种类别,它无法清晰地归入任何一侧。
ChatGPT Team 账户归雇主所有——在其中构建的所有 AI 上下文也归雇主所有。
当你使用公司的 ChatGPT Team 账户时,AI 对你学到的一切——你的思维方式、你项目的术语、你偏好的细节程度、你的判断框架——都存活在那个由雇主管理的工作区里。这些是从 你的 推理和专业知识中构建出来的,但它们存放在别人掌控的基础设施里。
当账户关闭时,这一切也随之关闭。OpenAI 自己的文档说得很清楚:当成员被从工作区中移除时,其对这些数据的访问也随之终止。在大多数 Team 和 Enterprise 配置下,个人贡献者并没有个人数据导出的权利。
这就产生了我们可以称之为 隐性离职成本 的东西——这种成本在 AI 成为日常工作工具之前并不存在,而且几乎没有任何公司目前将其纳入考量。
为什么"直接导出你的数据"解决不了这个问题
一个合理的回应是:你不能在离开之前直接导出 ChatGPT 对话吗?
在大多数公司账户里:不能。数据导出权属于工作区管理员。个人用户通常无法从由雇主管理的 ChatGPT Team 账户中导出对话数据。可以向 IT 部门确认,但别指望它。
即便可以导出,还有一个更深层的问题。对话日志并不等同于 AI 对 你这个人的模型。
让数月的 AI 协作真正高效的,不是原始的对话记录——而是通过数百次互动积累起来的隐性理解。AI 学到你总是希望列出取舍;你习惯以系统的方式思考;对你来说"简要概述"意味着三句话,而不是三段话。那种词汇。那种校准。这些才是难以重建的东西,它们并不存在于一个可导出的文件里。
业界新出现的迁移工具能——与不能——解决什么
Anthropic 于 2026 年 3 月推出的记忆导入工具——对于自愿进行平台切换来说,这是一次真正的进步。(来源:Anthropic)
2026 年 3 月 2 日,Anthropic 推出了 claude.com/import-memory:一个让你把提示粘贴到 ChatGPT,获取已保存记忆的结构化导出,然后导入到 Claude 的工具。无需技术配置,对所有用户免费,大约五分钟即可完成。
对于一个特定场景——有意地从 ChatGPT 切换到 Claude,并希望让你明确记下的偏好随之迁移——这是一个合适的工具。
但对于换工作这个问题,它不是合适的工具,原因有两个:
第一,它只会导入你 个人 的 ChatGPT 记忆——也就是与你个人 OpenAI 账户绑定的数据。如果你的上下文是在公司的 ChatGPT Team 账户里构建的,那就没有任何东西可供它导出。公司账户和个人账户是分开的;这个迁移工具只能触及后者。
第二,它只能捕捉已保存的记忆片段——那些 ChatGPT 正式记下的明确偏好。数月实际对话中累积起来的持续性上下文并不会迁移过去。你带走的是笔记,而不是理解。
对于换工作的人来说,这个官方工具解决的是一个并不适用于他们的场景:某个人拥有丰富的个人 ChatGPT 记忆,并希望迁移到 Claude。而在使用 ChatGPT Team 账户的公司里工作的大多数知识工作者,是在 公司 账户中构建上下文,而不是在个人账户中。
真正可移植的 AI 记忆是什么样的
 Memdex 跨平台捕捉你的 AI 协作上下文,并存储在你的个人账户里——而不是你雇主的账户。(来源:Memdex)
Memdex 跨平台捕捉你的 AI 协作上下文,并存储在你的个人账户里——而不是你雇主的账户。(来源:Memdex)
换工作这个问题需要一种不同的结构性方案:一开始就不存在于公司账户中的 AI 记忆。
Memdex 是一个围绕这一前提设计的浏览器扩展。当你使用 ChatGPT、Claude、Gemini 或其他 AI 工具时,Memdex 在后台运行——从实际使用中识别你的模式、术语、决策框架和工作风格。这些上下文存储在你 个人 的 Memdex 账户里,而不是在平台的基础设施里,也不在你雇主的工作区里。
 当你打开任何 AI 工具——在你当前的公司、下一家公司,或者一个全新的模型里——Memdex 都会自动注入你的个人上下文。(来源:Memdex)
当你打开任何 AI 工具——在你当前的公司、下一家公司,或者一个全新的模型里——Memdex 都会自动注入你的个人上下文。(来源:Memdex)
换工作时的实际差别在于:
- 仅使用公司账户: 你离开,账户关闭,在新的雇主那里从零开始重建。
- 使用 Memdex: 你离开,你的 Memdex 上下文随你而走,在新的岗位上你带着完整的 AI 协作历史上岗——无论新公司用的是哪种 AI 平台。
对于自愿的平台切换同样成立。当一个更好的模型发布、你想尝试它时,你的上下文已经在那里了。
在下一次换工作前保护你的 AI 上下文的步骤
你不必等到离职事件才行动。现在就可以落实几个切实可行的步骤:
搞清楚你的上下文存放在哪个账户里。 如果你的雇主提供了 AI 工具,你在里面构建的上下文就归那个账户所有。对于你想长期保留的职业 AI 上下文,请有意识地选择在哪里培养它。
用个人账户进行个人的职业发展。 用个人邮箱订阅的 Claude 或 ChatGPT,可以构建归你所有的上下文。用雇主的工具做雇主的工作;用个人账户培养你在职业生涯中沉淀的技能和模式。
定期导出你能导出的东西——不要等到辞职当天。 ChatGPT 和 Claude 都为个人账户提供数据导出选项。它们无法捕获一切,但能捕获一些。每季度做一次。
从一开始就独立地捕捉上下文。 这正是 Memdex 这类工具改变格局的地方。它不是最后时刻的迁移步骤,而是一个持续运行的后台层,确保你的 AI 协作历史在你的账户里增长,而不是在平台的账户里。
价值复利问题
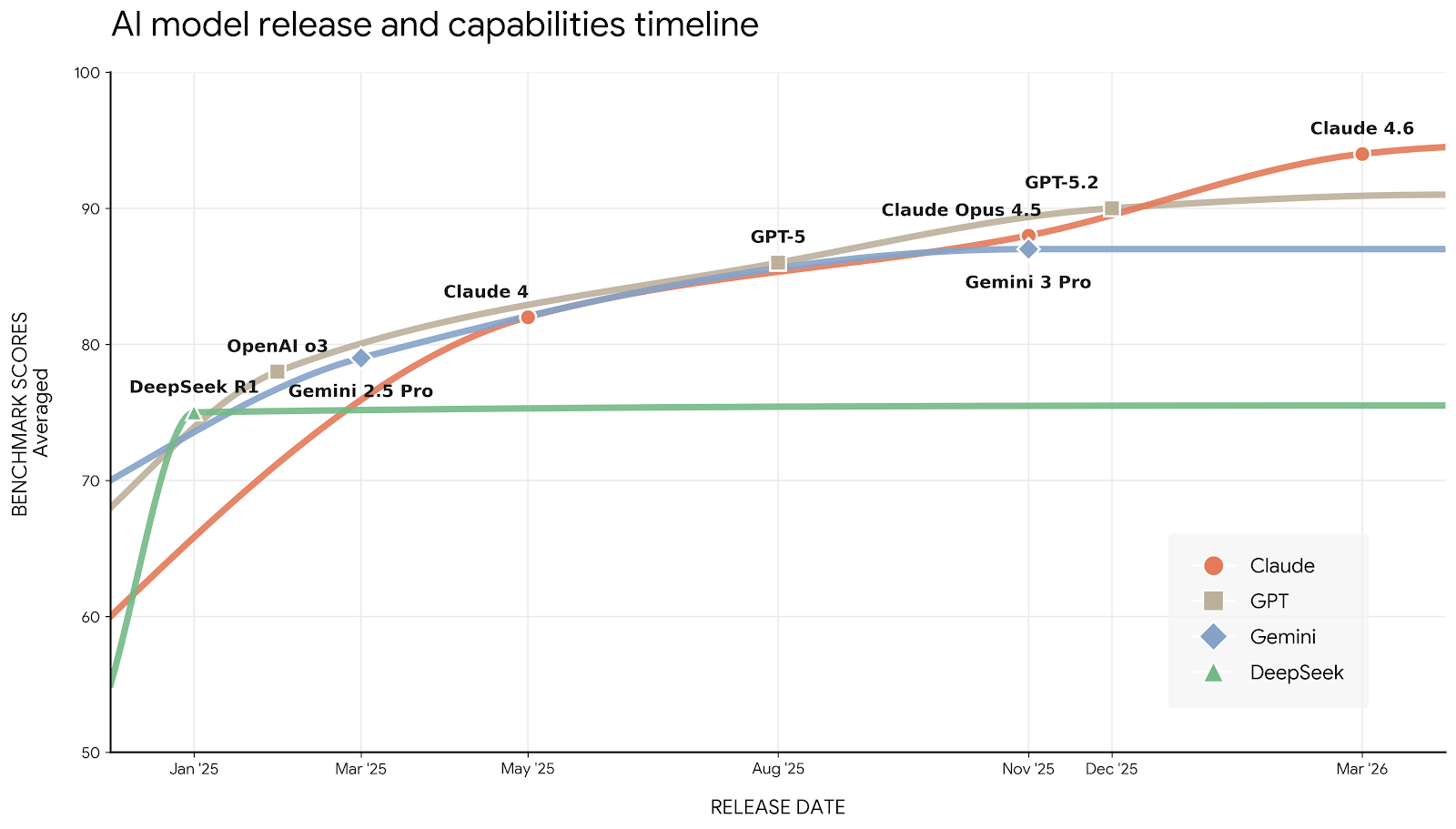 新的前沿模型每隔几周就会发布。拥有可移植记忆的用户能把每一次升级都利用起来——被锁在单一平台账户中的用户则每次切换都要从头开始。
新的前沿模型每隔几周就会发布。拥有可移植记忆的用户能把每一次升级都利用起来——被锁在单一平台账户中的用户则每次切换都要从头开始。
上方的 SOTA 图表显示了一件与换工作无关但同样相关的事:AI 能力是一个移动的靶子,而且移动得很快。GPT-5、Claude Opus 4.5、Gemini 3 Pro——每一个都代表着 AI 能为职业工作带来什么方面的实质性跃迁。
能从每一次新发布中获益最多的职业人士,是那些积累的上下文能够向前携带的人。他们不必在熟悉的模型(他们在那里有上下文)和更好的模型(他们会在那里从零开始)之间做选择。他们的上下文随之迁移,他们的生产力获得复利。
那些在每一次过渡时都从零开始重建的职业人士——每一次换工作、每一次平台切换、每一次模型升级——都在缴纳一笔随时间累积的税。这笔税你不去算的时候是看不见的:整个职业生涯中累计数周的重新上手时间,而且总是发生在你正试图在新地方证明自己的过渡期里。
常见问题
我离开公司后,我的 ChatGPT 记忆会怎样? 当你被从工作区中移除时,你就失去了访问权。记忆不会迁移到你的个人账户。你将从零开始。
我能从公司 ChatGPT 账户中导出对话历史吗? 在大多数配置下,不能。数据导出权属于工作区管理员,而非个人用户。请在离职日之前向 IT 部门确认,但别指望它。
Claude 的导入工具在这种场景下有用吗? 仅当你同时拥有一个保存了记忆的个人 ChatGPT 账户时才有用。它无法触及公司托管工作区内的内容。
我应该提前多久开始保护我的 AI 上下文? 现在。最好的时机是在你开始构建想要保留的上下文之前。次好的时机就是今天。
你的专业能力天然就是可移植的——你在换工作时总是带着自己的经验一起走。你的 AI 记忆也应该如此运作。而现在,对于大多数职业人士来说,它并没有。
解决办法并不复杂,而是结构性的:从一开始,就在一个你掌控的账户中构建你的 AI 协作上下文。
面向 Chrome、Edge 和 Firefox 的浏览器扩展。与 ChatGPT、Claude、Gemini 以及其他 AI 平台协同工作。